$ kafka-console-consumer --bootstrap-server localhost:9092 --from-beginning --topic twitter_json_01|jq '.Text' { "string": "RT @rickastley: 30 years ago today I said I was Never Gonna Give You Up. I am a man of my word - Rick x https://t.co/VmbMQA6tQB" } { "string": "RT @mariteg10: @rickastley @Carfestevent Wonderful Rick!!\nDo not forget Chile!!\nWe hope you get back someday!!\nHappy weekend for you!!\n❤…" }
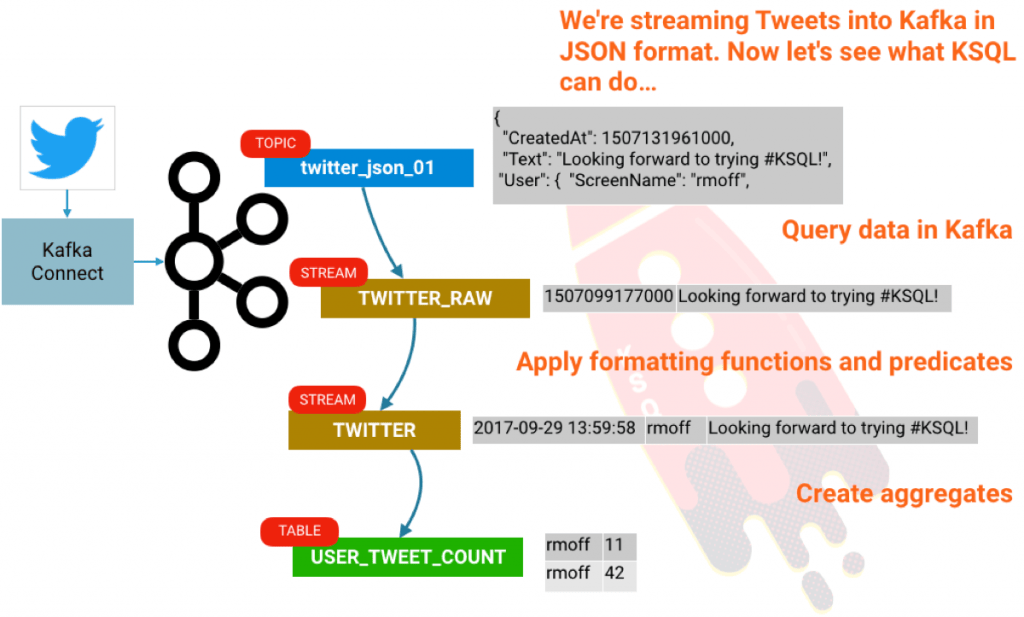
KSQL
现在我们从 KSQL 开始 ! 马上去下载并构建它:
1 2 3 4 5
cd /home/rmoff git clone https://github.com/confluentinc/ksql.git cd /home/rmoff/ksql mvn clean compile install -DskipTests
构建完成后,让我们来运行它:
1 2
./bin/ksql-cli local --bootstrap-server localhost:9092
ksql> SET 'auto.offset.reset' = 'earliest'; Successfully changed local property 'auto.offset.reset' from 'null' to 'earliest'
现在,让我们看看这些数据,我们将使用 LIMIT 从句仅检索一行:
1 2 3 4 5 6
ksql> SELECT text FROM twitter_raw LIMIT 1; RT @rickastley: 30 years ago today I said I was Never Gonna Give You Up. I am a man of my word - Rick x https://t.co/VmbMQA6tQB LIMIT reached for the partition. Query terminated ksql>
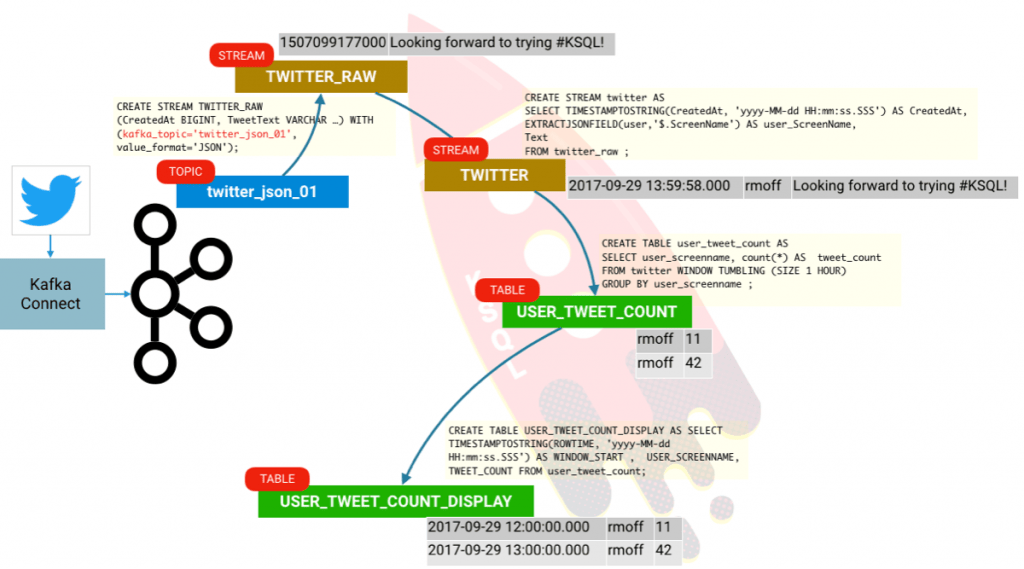
现在,让我们使用刚刚定义和可用的推文内容的全部数据重新定义该流:
1 2 3 4 5 6 7 8 9 10 11 12
ksql> DROP stream twitter_raw; Message -------------------------------- Source TWITTER_RAW was dropped
ksql> SELECT TIMESTAMPTOSTRING(CreatedAt, 'yyyy-MM-dd HH:mm:ss.SSS') AS CreatedAt,\ EXTRACTJSONFIELD(user,'$.ScreenName') as ScreenName,Text \ FROM twitter_raw \ WHERE LCASE(hashtagentities) LIKE '%oow%' OR \ LCASE(hashtagentities) LIKE '%ksql%';
2017-09-29 13:59:58.000 | rmoff | Looking forward to talking all about @apachekafka & @confluentinc’s #KSQL at #OOW17 on Sunday 13:45 https://t.co/XbM4eIuzeG
ksql> CREATE STREAM twitter AS \ SELECT TIMESTAMPTOSTRING(CreatedAt, 'yyyy-MM-dd HH:mm:ss.SSS') AS CreatedAt,\ EXTRACTJSONFIELD(user,'$.Name') AS user_Name,\ EXTRACTJSONFIELD(user,'$.ScreenName') AS user_ScreenName,\ EXTRACTJSONFIELD(user,'$.Location') AS user_Location,\ EXTRACTJSONFIELD(user,'$.Description') AS user_Description,\ Text,hashtagentities,lang \ FROM twitter_raw ;
Message ---------------------------- Stream created and running
ksql> DESCRIBE twitter; Field | Type ------------------------------------ ROWTIME | BIGINT ROWKEY | VARCHAR(STRING) CREATEDAT | VARCHAR(STRING) USER_NAME | VARCHAR(STRING) USER_SCREENNAME | VARCHAR(STRING) USER_LOCATION | VARCHAR(STRING) USER_DESCRIPTION | VARCHAR(STRING) TEXT | VARCHAR(STRING) HASHTAGENTITIES | VARCHAR(STRING) LANG | VARCHAR(STRING) ksql>
并且查询这个得到的流:
1 2 3 4 5 6
ksql> SELECT CREATEDAT, USER_NAME, TEXT \ FROM TWITTER \ WHERE TEXT LIKE '%KSQL%';
2017-10-03 23:39:37.000 | Nicola Ferraro | RT @flashdba: Again, I'm really taken with the possibilities opened up by @confluentinc's KSQL engine #Kafka https://t.co/aljnScgvvs
聚合
在我们结束之前,让我们去看一下怎么去做一些聚合。
1 2 3 4 5 6 7 8 9 10
ksql> SELECT user_screenname, COUNT(*) \ FROM twitter WINDOW TUMBLING (SIZE 1 HOUR) \ GROUP BY user_screenname HAVING COUNT(*) > 1;
ksql> CREATE TABLE user_tweet_count AS \ SELECT user_screenname, count(*) AS tweet_count \ FROM twitter WINDOW TUMBLING (SIZE 1 HOUR) \ GROUP BY user_screenname ;
Message --------------------------- Table created and running
看表中的列,这里除了我们要求的外,还有两个隐含列:
1 2 3 4 5 6 7 8 9 10
ksql> DESCRIBE user_tweet_count;
Field | Type ----------------------------------- ROWTIME | BIGINT ROWKEY | VARCHAR(STRING) USER_SCREENNAME | VARCHAR(STRING) TWEET_COUNT | BIGINT ksql>
我们看一下这些是什么:
1 2 3 4 5 6 7 8 9 10 11 12
ksql> SELECT TIMESTAMPTOSTRING(ROWTIME, 'yyyy-MM-dd HH:mm:ss.SSS') , \ ROWKEY, USER_SCREENNAME, TWEET_COUNT \ FROM user_tweet_count \ WHERE USER_SCREENNAME= 'rmoff';