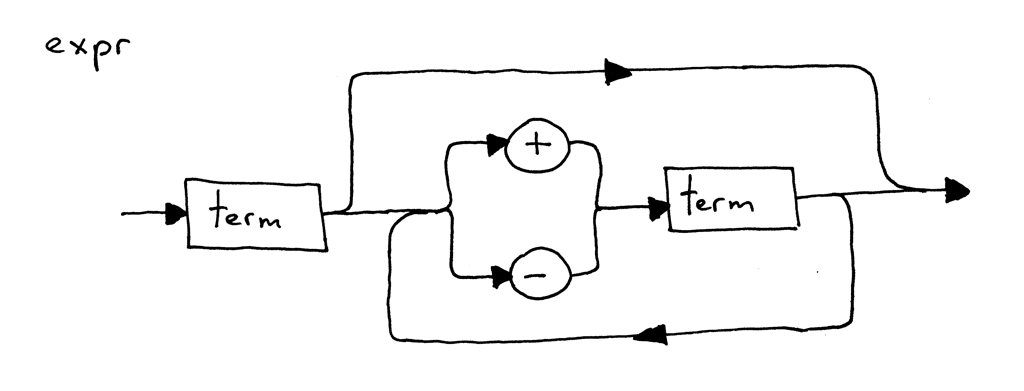
result = self.term() while self.current_token.type in (PLUS, MINUS): token = self.current_token if token.type == PLUS: self.eat(PLUS) result = result + self.term() elif token.type == MINUS: self.eat(MINUS) result = result - self.term()
return result
因为解释器需要评估一个表达式, term 方法被改成返回一个整型值,expr 方法被改成在合适的地方执行加法或减法操作,并返回解释的结果。尽管代码很直白,我建议花点时间去理解它。
def advance(self): """Advance the `pos` pointer and set the `current_char` variable.""" self.pos += 1 if self.pos > len(self.text) - 1: self.current_char = None # Indicates end of input else: self.current_char = self.text[self.pos]
def skip_whitespace(self): while self.current_char is not None and self.current_char.isspace(): self.advance()
def integer(self): """Return a (multidigit) integer consumed from the input.""" result = '' while self.current_char is not None and self.current_char.isdigit(): result += self.current_char self.advance() return int(result)
def get_next_token(self): """Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence apart into tokens. One token at a time. """ while self.current_char is not None:
if self.current_char.isspace(): self.skip_whitespace() continue
if self.current_char.isdigit(): return Token(INTEGER, self.integer())
if self.current_char == '+': self.advance() return Token(PLUS, '+')
if self.current_char == '-': self.advance() return Token(MINUS, '-')
result = self.term() while self.current_token.type in (PLUS, MINUS): token = self.current_token if token.type == PLUS: self.eat(PLUS) result = result + self.term() elif token.type == MINUS: self.eat(MINUS) result = result - self.term()
return result
def main(): while True: try: # To run under Python3 replace 'raw_input' call # 要在 Python3 下运行,请把 ‘raw_input’ 的调用换成 ‘input’ text = raw_input('calc> ') except EOFError: break if not text: continue interpreter = Interpreter(text) result = interpreter.expr() print(result)